How to adapt your AE plugin for 8, 16, 32bit color
Hello. In previous article “First After Effects Effects-Plug-In Development“, I implemented a simple After Effects plugin. This article is supplement to it.
What is color (bit) depth
Colors are represented as numbers in computers. In RGB color system, color is represented (R, G, B) such as (100, 120, 144) or (0.5, 0.2, 0.7). In gray scale mode, color is represented as one value such as a integer form 0 to 255 or float from 0 to 1.0.
Color bit depth is resolution of each values. When the color is 8 bpc(bit per channel) each channel, R, G, B and A is expressed using 8bit. When the color is 8bpp(bit per pixel), each pixel color is expressed using 8bit, 3bit for R and G and 2 bit for B.
The following is the image of the difference between 4bit color (4bpc) and 8bit color (8bpc).
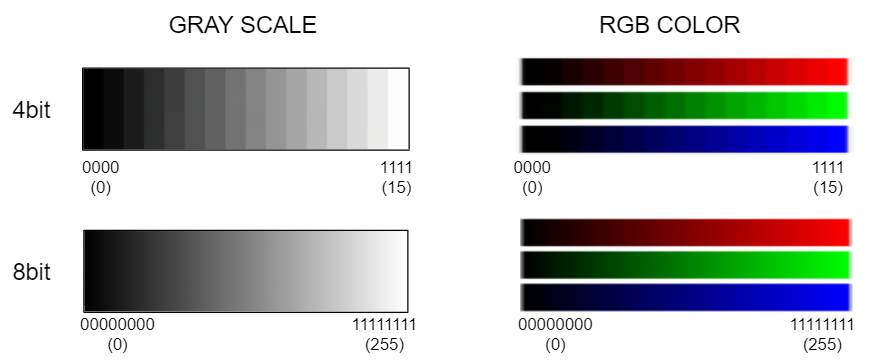
Color bit depth in After Effects
In After Effects, you can use 8-bpc, 16-bpc, or 32-bpc color. (check “Color depth and high dynamic range color” for details)
8bit: 0-255 for each channel (256 gradation)
16bit: 0-32767 for each channel (32,768 gradation)
32bit: The range represented by a 32-bit float for each channel (4,294,967,296 gradation)
The color is represented by integer in 8bpc and 16bpc color. Float value is clamped into [0.0 – 1.0] and convert to [0-255] or [0-32767] in 8bpc and 16bpc.
Color bit depth in AE plug-in development
When you develop After Effects plug-in, you should consider all color 8/16/32bit.
8bit
8ARGB color is stored using PF_Pixel8
//this is from AE_Effect.h
// Basic pixel defn's
typedef struct {
A_u_char alpha, red, green, blue;
} PF_Pixel;
typedef PF_Pixel PF_Pixel8;
typedef PF_Pixel PF_UnionablePixel;16bit
//this is from AE_Effect.h
typedef struct {
#ifdef PF_PIXEL16_RENAME_COMPONENTS
// this style is useful for debugging code converted from 8 bit
A_u_short alphaSu, redSu, greenSu, blueSu;
#else
A_u_short alpha, red, green, blue;
#endif
} PF_Pixel16;32bit
32bit color is supported in CS6 (11.0) and more.
//this is from AE_Effect.h
typedef A_FpShort PF_FpShort;
typedef A_FpLong PF_FpLong;
typedef struct {
PF_FpShort alpha, red, green, blue;
} PF_PixelFloat, PF_Pixel32;And as you can see below, each channel is char type (8bit) in PF_Pixel or PF_Pixel8, unsigned short type (16bit) in PF_Pixel16 and float type (32bit) in PF_PixelFloat or PF_Pixel32.
//picked up from A.h typedef char A_char; typedef float A_FpShort; typedef unsigned short A_u_short;
Tips of color depth handling in AE plug-in development
Global setup
To make your effect handle 16-bpc color, set out_data->out_flags PF_OutFlag_DEEP_COLOR_AWARE.
And to make your effect supports 32-bpc colors, set out_data->out_flags2 PF_OutFlag2_FLOAT_COLOR_AWARE and PF_OutFlag2_SUPPORTS_SMART_RENDER.

Set pixel format
Before CS6, PF_CHECKOUT_PARAM() only returned 8-bit ARGB buffers, regardless of the pixel format currently being used for rendering. Starting in CS6, an effect can opt in to get frames in the same format as the render request, whether it is 32-bit float, YUV, etc.
from After Effects SDK Guide

Render
In Render function, the iterate function scan input flame and calculate output frame as pixel to pixel operation, pixel function. The iterate functions is selected separately depending on the PrPixelFormat of destination pixels. Check After Effects SDK Guide “Progress During Iteration” for details.

Smart Render
In Smart Render function, pixel functions is selected separately depending on the PrPixelFormat like Render function.
If you want to know about the difference between Render function and SmartRender function, check the article “The difference of Render and Smart Render in After Effects”. (sorry, it will come soon)

The conditional branch by switch sentence is following.
switch (format) {
case PF_PixelFormat_ARGB128:
iterateFloatSuite ->iterate(
in_data, 0, output_worldP->height, input_worldP,
NULL, (void*)infoP, FilterImage32, output_worldP);
break;
case PF_PixelFormat_ARGB64:
iterate16Suite ->iterate(
in_data, 0, output_worldP->height, input_worldP,
NULL, (void*)infoP, FilterImage16, output_worldP);
break;
case PF_PixelFormat_ARGB32:
iterate8Suite ->iterate(
in_data, 0, output_worldP->height, input_worldP,
NULL, (void*)infoP, FilterImage8, output_worldP);
break;
default:
err = PF_Err_BAD_CALLBACK_PARAM;
break;
}Pixel functions
Prepare each functions for 8/16/32 bit separately. The follow example is in SDK_Noise.cpp.
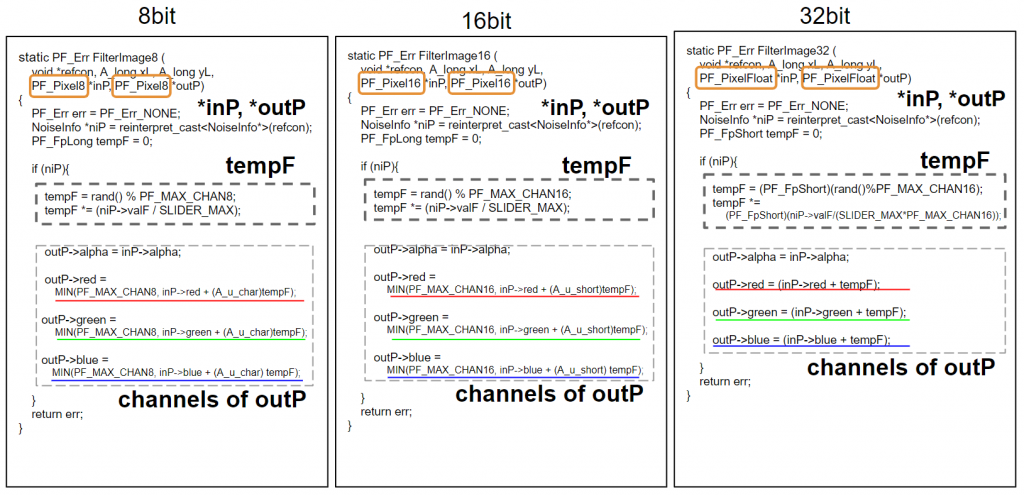
The differences are following.
*inP and *outP
// 8bit
static PF_Err FilterImage8 (
void *refcon, A_long xL, A_long yL,
PF_Pixel8 *inP, PF_Pixel8 *outP)
// 16bit
static PF_Err FilterImage16 (
void *refcon, A_long xL, A_long yL,
PF_Pixel16 *inP, PF_Pixel16 *outP)
// 32bit
static PF_Err FilterImage32 (
void *refcon, A_long xL, A_long yL,
PF_PixelFloat *inP, PF_PixelFloat *outP)tempF
// 8bit clamp in range [0, PF_MAX_CHAN8] tempF = rand() % PF_MAX_CHAN8; tempF *= (niP->valF / SLIDER_MAX); // 16bit clamp in range [0, PF_MAX_CHAN16] tempF = rand() % PF_MAX_CHAN16; tempF *= (niP->valF / SLIDER_MAX); // 32bit clamp in range [0, 1 = PF_MAX_CHAN16/PF_MAX_CHAN16] tempF = (PF_FpShort)(rand() % PF_MAX_CHAN16); tempF *= (PF_FpShort)(niP->valF / (SLIDER_MAX * PF_MAX_CHAN16));
channels of outP
// 8bit clamp in the range [0, PF_MAX_CHAN8] outP->red = MIN(PF_MAX_CHAN8, inP->red + (A_u_char) tempF); // 16bit clamp in the range[0, PF_MAX_CHAN16] outP->red = MIN(PF_MAX_CHAN16, inP->red + (A_u_short) tempF); // 32bit outP->red = (inP->red + tempF);