PointNet, deep neural network that consumes point cloud.
Today I’ve read the paper “PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation” by Charles R. Qi, Hao Su, Kaichun Mo, Leonidas J. Guibas.
What is PointNet?
PointNet is a neural network that directly consumes point cloud, unordered point set. While the architecture is simple, it provides an approach to object classification, part segmentation and semantic segmentation with a good performance.
Novelty of the study
While typical CNN requires volume data, like voxel, or a collection of images, these representations cause a lack of detail while the sampling process. So PointNet take point clouds directly as an input. The input is (x, y, z) coordinates of N points, which are given in no particular order.
Applications of PointNet
PointNet can perform well in 3 tasks below.
- 3D Object Classification
- 3D Object Part Segmentation
- Semantic Segmentation in Scene
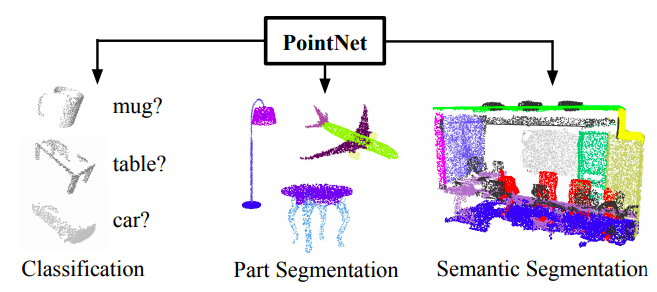
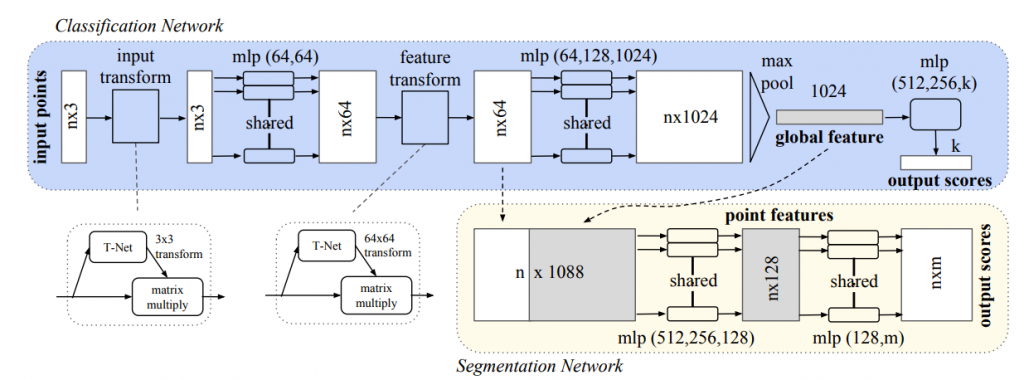
Architecture
overall
Each one of input points is input to the same mlp(Multilayer perceptron), and features are extracted.
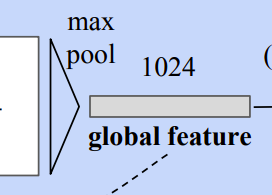
Symmetric function
As a strategy to make a model invariant to input permutation, a symmetric function is used. A symmetric function is the function whose value is the same no matter the order of the given n arguments, n points in this case. In this model, the symmetric function is mlp network and max-pooling which aggregates point features.
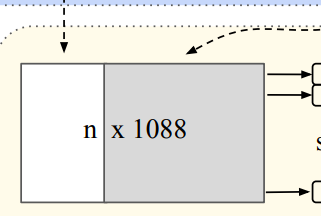
Local and global information aggregation
Both the local and global information is required for point segmentation. PointNet concatenate the global feature with point features and extract new per point features.
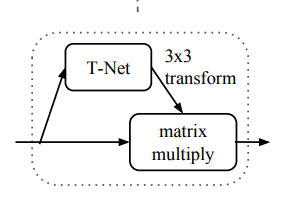
Invariance to the transformation
The semantic labeling need to be invariant to geometric transformations of shapes. PointNet predicts an affine transformation matrix by a mini-network (T-Net). The mini-network is composed by basic modules of feature extraction, max pooling and fully connected layers.
Visualization
They visualize critical point sets and upper-bound shapes in this paper. It enables us to summarize an input point cloud by a sparse set of key points.